本文介绍基于Python中的ArcPy模块,将大量遥感影像文件按照分幅条带编号与成像时间加以分组,并将同一分幅的遥感影像加以每个8天时间间隔内的镶嵌拼接的方法。
首先,来看一下本文具体的需求。我们现有一个文件夹,其中含有大量的.tif格式的遥感影像,如下图所示。首先,每一景遥感影像的文件名中,都有一个表示成像时间的字段;例如,下图中从上往下数第1景图像,就是2022年第001天某时刻的遥感影像,而下图中从上往下数第4景图像,就是2022年第013天某时刻的遥感影像。

同时,这些遥感影像文件的文件名顺序还不完全是时间顺序,因为其文件名开头还有一些表示其他含义的字段(如传感器名称),而这些不同字段对应的遥感影像文件同样具有多个成像时间。如下图所示,可以看到在GF1WFV3传感器对应的2022年346天遥感影像结束后,新的GF1WFV4传感器对应的遥感影像又是从2022年的开头开始的。总之,就是不能将文件名排序作为遥感影像成像时间的顺序。
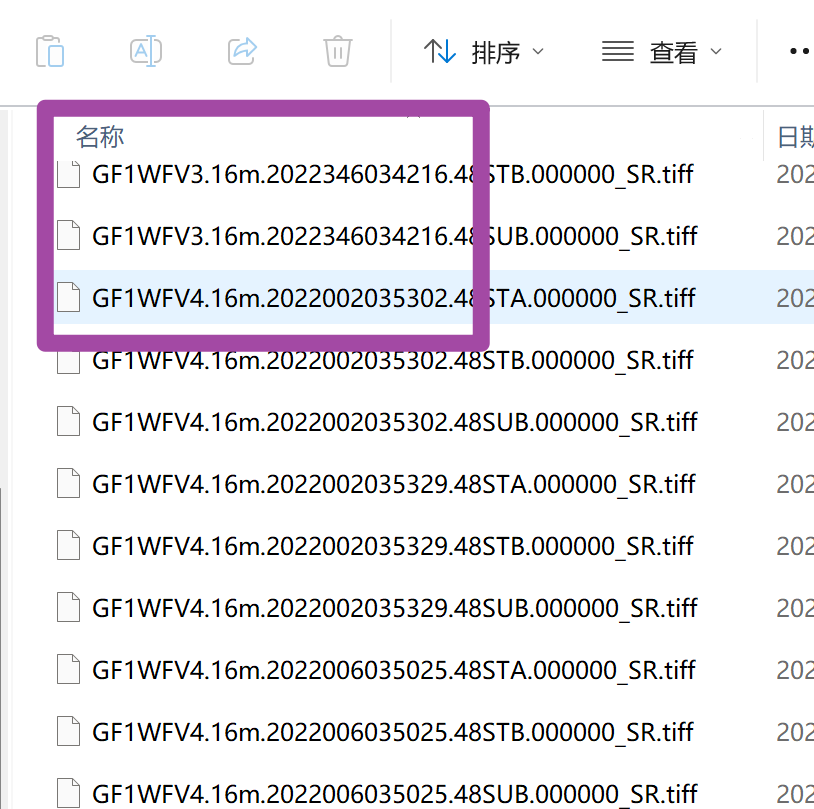
其次,如下图所示,每一景遥感影像的文件名中还有一个表示遥感影像分幅的字段;其中,48STA与48STB等都是不同分幅对应的编号。

我们希望实现的是,从2022年第001天开始,到第365天结束,对于每1个分幅,将其每1个8天时间范围内的所有遥感影像(无论是来自哪一个传感器)拼接在一起。例如,将分幅为48STA的、成像时间在001天至008天的遥感影像拼接在一起,然后将009天至016天的拼接在一起,以此类推,直到2022年所有分幅为48STA的遥感影像处理完成;随后再处理48STB的,再以此类推,直到全部分幅都处理完成。
在之前的文章Google Earth Engine谷歌地球引擎GEE批量计算一年中每个指定天数范围内遥感影像平均值的方法(https://blog.csdn.net/zhebushibiaoshifu/article/details/135447348)中,我们介绍过在GEE中计算每1个8天时间间隔内遥感影像数据平均值的方法;而这一次我们将基于Python,将每1个8天时间间隔内遥感影像拼接起来。
本文所用到的代码如下。
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 13 22:44:34 2024
@author: fkxxgis
"""
import re
import os
import arcpy
arcpy.env.workspace = r"F:\Data_Reflectance_Rec\GF\2022"
output_folder = r"F:\Data_Reflectance_Rec\GF\8Days_frame\2022"
image_list = arcpy.ListRasters("*", "tiff")
image_list.sort()
image_dict = {}
for image in image_list:
match = re.search(r"\d{7}", image)
image_date = match.group()
image_year = image_date[0:4]
image_days = image_date[-3:]
match = re.search(r"\.(.{5})\.", image)
image_frame = match.group().strip(".")
dict_idx = (int(image_days) - 1) / 8
dict_key = str(dict_idx) + "/" + image_frame
if dict_key in image_dict:
image_dict[dict_key].append(image)
else:
image_dict[dict_key] = [image]
print image, "is in", dict_key
for dict_idx, image_list_interval in image_dict.items():
dict_idx_split = dict_idx.split("/")
days = int(dict_idx_split[0]) * 8 + 1
frame = dict_idx_split[1]
template_image = image_list_interval[0]
cell_size = arcpy.GetRasterProperties_management(template_image, "CELLSIZEX")
value_type = arcpy.GetRasterProperties_management(template_image, "VALUETYPE")
describe = arcpy.Describe(template_image)
spatial_reference = describe.spatialReference
arcpy.CreateRasterDataset_management(output_folder,
image_year + str(days).zfill(3) + "_" + frame + ".tif",
cell_size.getOutput(0),
"16_BIT_UNSIGNED",
spatial_reference,
4)
print image_year + str(days).zfill(3) + "_" + frame + ".tif", "creation finished."
try:
arcpy.Mosaic_management(image_list_interval,
os.path.join(output_folder, image_year + str(days).zfill(3) + "_" + frame + ".tif"),
"MINIMUM",
background_value = 0,
nodata_value = 0)
# arcpy.MosaicToNewRaster_management(image_list_interval,
# output_folder,
# image_year + str(days).zfill(3) + "_" + frame + ".tif",
# pixel_type = "16_BIT_UNSIGNED",
# number_of_bands = 4,
# mosaic_method = "MINIMUM")
print image_year + str(days).zfill(3) + "_" + frame + ".tif", "mosaic finished."
except arcpy.ExecuteError:
print image_year + str(days).zfill(3) + "_" + frame + ".tif", "had ERROR."
其中,上述代码的具体含义如下。
首先,我们通过import语句导入所需的模块。其中,re用于正则表达式匹配,os用于文件路径操作,arcpy是ArcGIS的Python模块,用于处理GIS数据。
随后,我们通过env.workspace设置工作空间,即等待拼接的栅格影像数据所在的文件夹路径;通过output_folder设定输出结果的文件夹路径。
接下来,基于ListRasters("*", "tiff")获取待拼接的所有.tif格式栅格文件,并将其排序后存储在image_list列表中;image_dict是一个字典,用于存储栅格影像按日期和分幅号进行分组的结果,从而将每1种分幅中,处于同1个8天时间间隔的遥感影像放在一起;for循环遍历image_list中的每个影像文件,并使用正则表达式re.search提取影像文件名中的日期信息——其中,需要提取年份image_year和天数image_days;接下来,使用正则表达式re.search提取影像文件名中的分幅号信息,并根据天数和分幅号生成字典的键dict_key;随后,将影像文件添加到相应的字典值中,如果字典键已存在,则将影像文件添加到对应的列表中。同时,打印信息,指示影像文件属于哪个字典键。
再次,for循环遍历image_dict中的每个字典键和对应的影像文件列表——首先拆分字典键,获取天数和分幅号的信息;接下来,获取文件列表中第一个影像文件的信息,如像元大小、值类型、空间参考等(因为后期需要基于其来作为模板图像);随后,使用CreateRasterDataset_management()函数创建输出栅格数据集,命名规则为年份+天数+分幅号。同时,打印信息,指示栅格数据集创建完成。
最后,即可使用Mosaic_management()将影像文件列表拼接为一个栅格数据集,命名规则同上;同时,打印信息,指示栅格数据集拼接完成。如果拼接过程中出现错误,则捕获arcpy.ExecuteError异常,并打印错误信息。这里之所以需要try和except语句,是因为有的8天时间间隔内可能没有任何遥感影像数据,因此Mosaic_management()函数可能会报错,导致程序终止运行。关于try和except语句的具体用法,大家参考Python异常处理try与except跳过报错使得程序继续运行的方法(https://blog.csdn.net/zhebushibiaoshifu/article/details/137552214)即可。
运行上述代码,首先将看到如下图所示的界面;表示正在基于遥感影像的文件名,将其放置到不同的字典中——这个字典就是根据遥感影像成像时间与分幅号来表示的。

完成字典的确定后,相同分幅号且落在同1个8天时间间隔内的遥感影像数据,即可被存入同1个字典中。接下来,即可开始拼接;如下图所示。

完成上述代码运行后,即可在结果文件夹中看到按照分幅号与成像时间拼接好的遥感影像了。因为我这里当初把2022年的拼接结果误删了,所以就截取2021年的数据经过上述代码处理后的结果,如下图所示。可以看到,结果已经是按照每个8天的时间间隔、以及每1种分幅号拼接好的了。
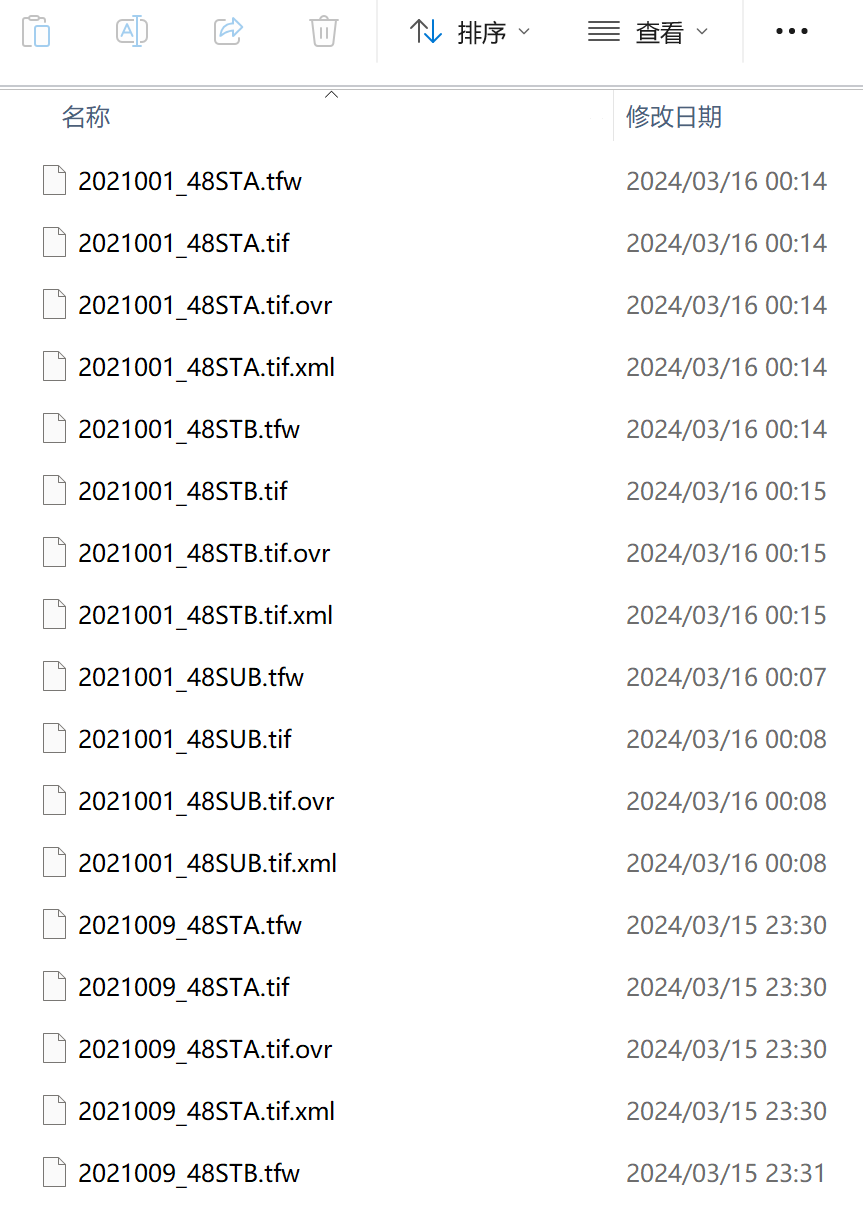
至此,大功告成。
欢迎关注:疯狂学习GIS